Статистический анализ выборов парламента Грузии: хвост правящей партии начинает отрастать
Выборы в грузинский парламент состоялись 8 октября 2016 года. Для анализа используются данные на 12:00 11.10.2016. Они содержат результаты по 3.683 избирательным участкам. Также проводятся сравнения с данными президентских выборов в 2013 году, о которых я подробно ранее в ЖЖ. Данные разместил в интернете.
Резюме
Основной задачей было установить тренд за последние три года: насколько изменилась избирательная система за время правления президента Маргвелашвили. Можно с уверенностью сказать, то ситуация осталась на хорошем уровне, аналогичном уровню 2013 года.
На уровне страны существенных аномалий обнаружить не удалось. Однако, прослеживаются аномалии в зависимости от уровня поддержки партии Грузинская Мечта (Georgian Dream, далее GD).
Треть округов с наибольшей поддержкой GD имеют небольшие отклонения (причём в пользу этой партии). Это отклонения увеличились с 2013 года. Там же обнаруживается повышенные, хотя и незначительные, следы манипуляций с цифровыми данными.
В трети округов с худшими для GD результатами - и видимо лучшими для партии Единого Национального Движения (United National Movement, далее UNM) - такие отклонения были в 2013 году, но в 2016 исчезли.
Также нормально выглядят данные в средней трети округов.
Уровень общих искажений остался на том же уровне, благодаря тому, что одна партия их увеличила, а другая полностью потеряла, уступив свое лидерство. Партии поменялись местами.
Можно сделать предположение, что UNM потеряла нестатистические, i.e. административные возможности влиять на результаты выборов, а GD их нарастила. Это согласуется с тем фактом, что GD три года обладала полной властью, как парламентской, так и президентской.
То есть это влияние перестало компенсироваться аналогичным влиянием противоборствующей стороны, и дальнейшее наращивание этих возможностей может начать негативно сказываться на всей избирательной системе.
Несмотря на малый масштаб, обнаруженные отклонения и манипуляции могли привести также к искажению состава парламента, так как одной из партий не хватило 0.38%, для преодоления порога прохождения.
Графические методы
Распределение числа УИК по процентам за лидеров избирательной гонки носит нормальный, ожидаемый характер (тут и далее все иллюстрации кликабельны).

(гауссы построены методом автоматического подбора по минимальной сумме модулей отклонения от наблюдаемых величин, и даются для иллюстрации)
Симметричные колокообразные кривые неплохо описываются распределением Гаусса. Так выглядят подобные распределения в большинстве стран с единым избирательным округом и честными выборами.
Аналогично подобные распределения выглядели в 2013 году, на выборах президента Грузии:

В 2016 году обращает на себя внимание группа УИКов с максимальными процентами за GD.
Во-первых, они находятся значительно выше кривой, т.е. являются аномальными для общей по стране статистики. Это может вызвано как зоной особых электоральных предпочтений, так и зоной повышенных манипуляций.
Во-вторых, за 3 года этот сектор аномальной зоны с хорошими для партии власти результатами увеличился. Подобные процессы в России сигнализировали о начале деградации избирательной системы. Деградация увеличивалась вместе с ростом этой зоны.
В-третьих, из сравнения с 2013 годом видно, что «партии поменялись местами». Обладавшая подобной аномалией UNM её лишилась, а GD её увеличила. Это лишний раз подчеркивает, связь подобных аномалий с административным ресурсом.

В целом же отклонения от ожидаемых общих по стране величин невелики.
Характер распределения голосов малых партий также не обнаруживает серьезных аномалий. Единственная особенность – пик нулевых результатов вызван близостью к началу координат.

В целом он был аналогичен распределению голосов за тех кандидатов в президенты в 2013, которые набрали небольшое количество голосов.

Большой интерес представляет сравнение столичной области и периферии. Повышенная политическая активность в столице может создавать серьезные препятствия для фальсификаций и искажений. Можно сделать ряд выводов из сравнения результатов в столице и вне нее. В такой небольшой по территории и населению стране как Грузия различия между столицей и регионом должны быть небольшими. А сильные различия говорили бы об искажении волеизъявления (как это происходит, например, в Армении).
Характер распределений для Тбилиси и вне его таков (мы считаем столичными 1-22 избирательные округа):
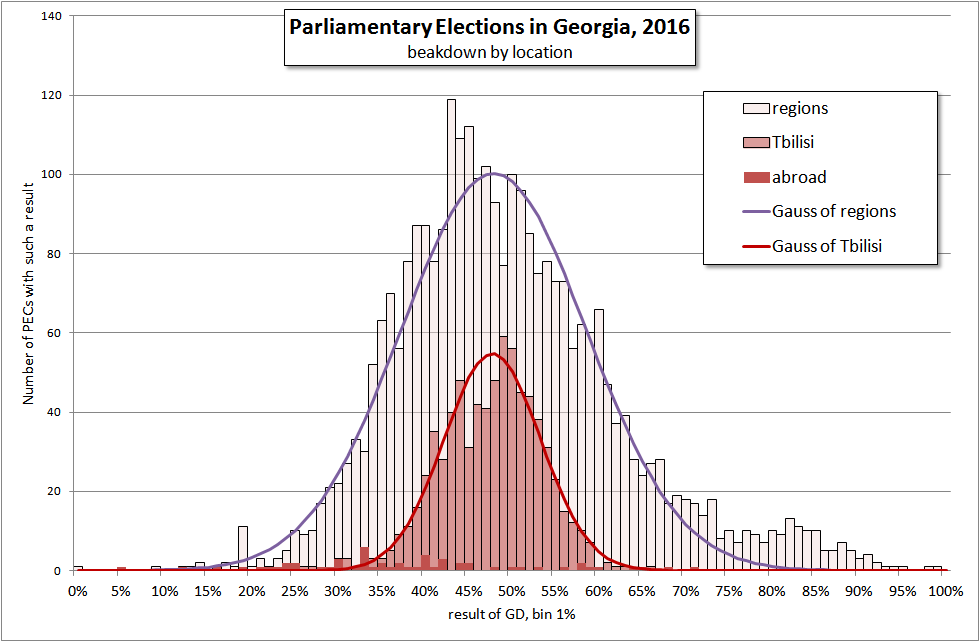
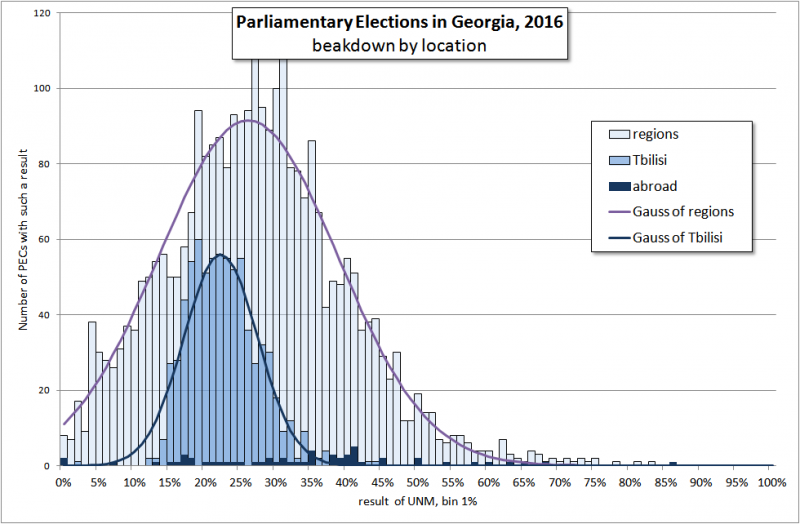
В целом, те же хорошо сгруппированные колоколобразные кривые, неплохо описываемые Гауссом. Интересно сравнить полученные распределения с аналогичными гистограммами 2013 года.


Во-первых, столичный график стал менее монотонным и симметричным. Возможно, это связано с изменением границ округов. Не зная местной специфики трудно судить о причинах этого явления. Хотя число УИК в 2013 и 2016 годах приблизительно одинаково (752 и 738 соответственно), но визуально ситуация поменялась.
2013 год:

2016 год:

С другой стороны, возможно, эти неравномерности - раскол внутри столичного электората или поиск новых лидеров. Видно, что относительно остальной части страны, столица сдвинулась влево (в сторону меньших предпочтений) как по отношению к GD так и UNM. А возможно, идет подстройка под столицу (или столицы под страну?). Примечательно, что раньше столица была аккуратно в центре страны по отношению к UNM (правящей или «недавно правящей» партии). Теперь столица в центре по отношению GD, ныне правящей партии.
Во-вторых, искажений на правом, благоприятном, плече у UNM не осталось даже в регионах, как это было в 2013 году. И именно в регионах GD приобрела тот же «родовой хвост» правящей партии. Столицу, как мы и ожидали, такие искажения не касались в 2013 и не коснулись в 2016.
Для уточнения источника этих искажений, можно разбить все округа на 3 большие равные группы, в зависимости от уровня поддержки GD в них.

В результате получается следующая картина:
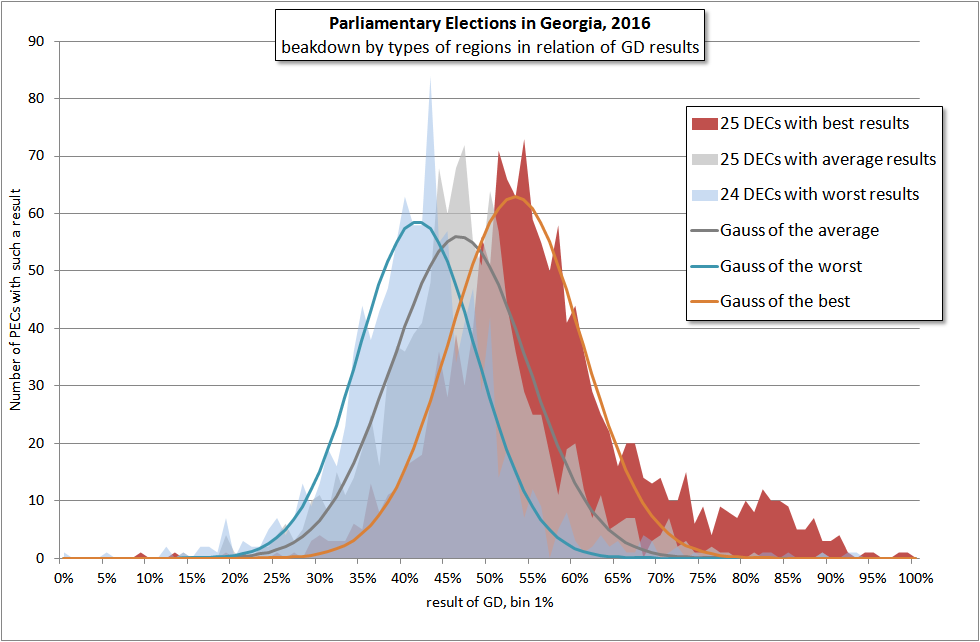
Во-первых, пришлось отказаться от представления в виде гистограмм: группы настолько близки друг к другу, что такое представление потеряло бы наглядность.
Во-вторых, как и раньше, гауссы даются лишь для иллюстрации. Но, так как искажение распределения становится всё более явным, гауссы построены в предположении, что если и имели место преднамеренные искажения, то они происходили в целях улучшения благоприятного результата для каждой из сторон. А именно, для левого, про-UNM набора округов – по правому плечу распределения, для среднего – по обоим, для правого, про-GD набора – по левому плечу. Если стороны и искажали результат, то никак не во вред себе.
Тем не менее, левая и средняя диаграмма симметрична и не искажена, и лишь в про-GD наборе наблюдается явная асимметрия. Нечто подобное происходило и в 2013 году:

Однако тогда обе стороны имели искажения в свою пользу в своих регионах. По сравнению с 2013 годом, можно сказать, что UNM потеряла способность «передвигать» УИКи в свою пользу, а GD усилила такую способность. Можно сделать предположение, что UNM потеряла нестатистические, i.e. административные возможности влиять на результаты выборов, а GD её нарастила. Это согласуется с тем фактом, что GD три года обладала полной властью, как парламентской, так и президентской.
Более того, для 2013 мы оцениваем «перетягивание каната» в области аномальных распределений как 287:167 УИК, т.е. 120 УИК в пользу UNM (по числу УИК находящихся над кривой). В 2016 году UNM этот канат отпустила: 180:0 УИК в пользу GD. Говорят, что при резком отпускании каната система может потерять равновесие, а противники падают, хотя и в противоположные стороны.
Основной вклад в аномальный хвост GD в 2016 году сделал округ №53. Результатов за GD ниже 75.7% там вообще нет.
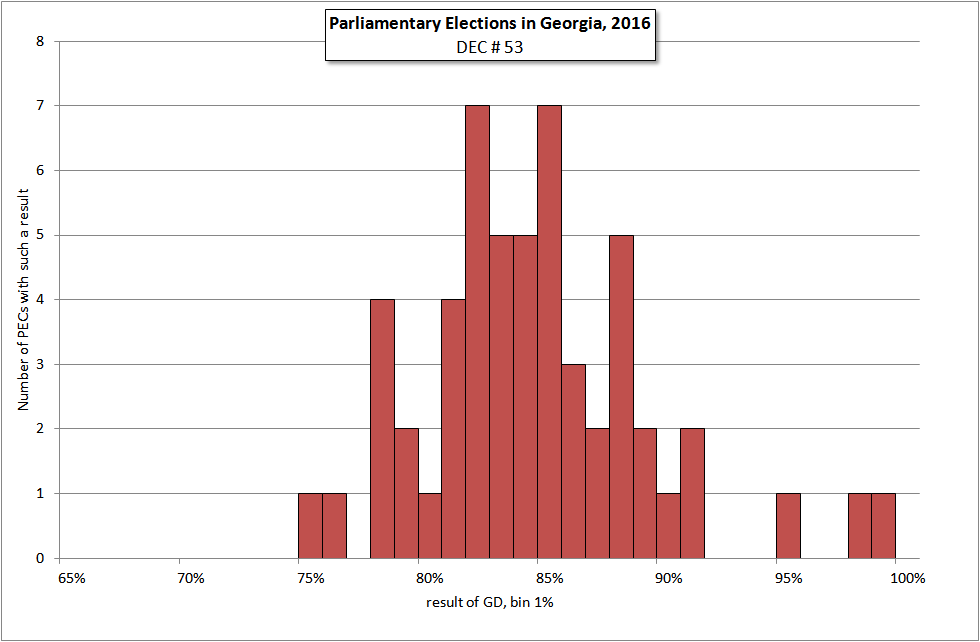
В 2013 году основной вклад в аномальный хвост GD делал округ №50. Там кандидат GD набрал рекордные 94.21% голосов. УИК с результатами ниже 88% тоже не было.
В 2013 году это выглядело так:

В данных за 2013 год, были замечены характерные числовые аномалии. Максимальные результаты: 100% голосов за кандидата GD (УИК 29 и 46) Серия круглых цифр: 600 голосов за него (УИК 37 и 51), 300 голосов (УИК 52) абсолютная явка: 700 избирателей (УИК 42).
Более детальный анализ по частое последней цифры также привлекает внимание:

Мы видим, что в округе 50, в том диапазоне, который изначально вызывал у нас сомнения, появление 0 и 5 в результатах GD, которые тоже казались аномальными, более чем в 1.5 раза выше ожидаемых.
Хотя Критерий согласия Пирсона, или критерий согласия χ 2, для данного набора голосов GD в округе №50 не вызывает тревогу (8.69, т.е. вероятность что это «игра случая» - 53%), он не учитывает психологические особенности, описанные ниже.
Более того, в численных данных встречаются и другие аномалии. Так, выглядят последние цифры в худших для GD округах в 2013 году:
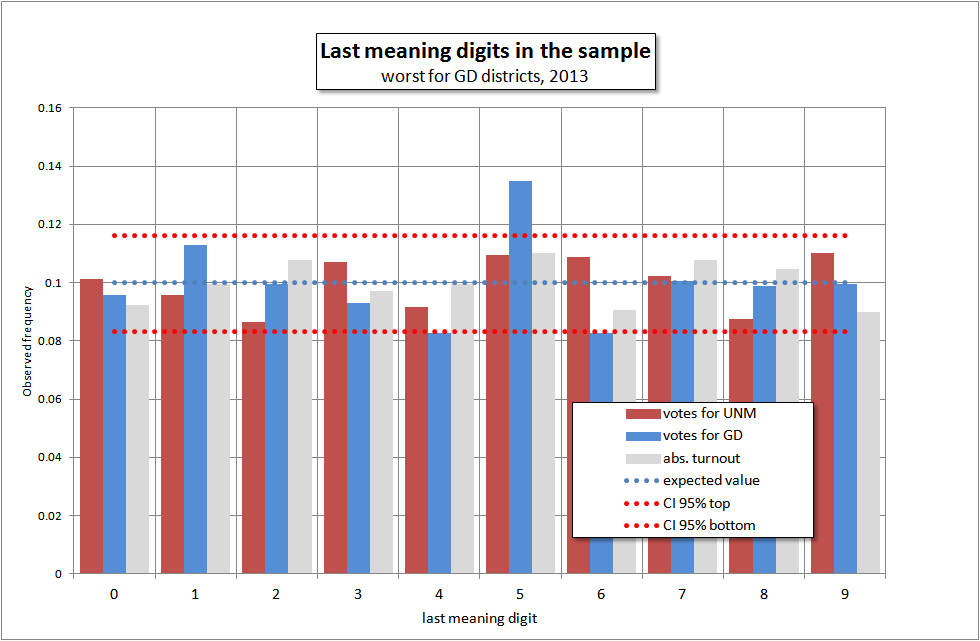
Расчеты показывают, что вероятность такого случайного стечения обстоятельств – 0.3% (χ 2 = 25.13). В таких случаях принято отвергать гипотезу, в данном случае о случайном характере наблюдаемых нами цифр. Другими словами, с вероятностью 99.7% цифры кто-то правил. Мы не можем сказать, за GD или против неё были произведены такие манипуляции, но при подобных величинах χ 2 принято принимать это за факт.
Та же странная тенденция любви к цифре «5» подтвердилась и в 2016 году (см. ниже)
Эти и другие подобные наблюдения вынуждают нас перейти от графических методов к численным.
Численные методы
В отличие от графических, численные методы позволяют высчитывать статистические вероятности манипуляций. С другой стороны они позволяют лишь установить факт манипуляций, не давая информации кто, зачем и с каким результатом это делал.
Статистическая проверка гипотез имеет ещё один недостаток: т.н. ошибки первого рода, или «ложные срабатывания». Например, если наблюдаемые величины вышли за доверительный интервал в 95% принято отвергать гипотезу. Однако если у нас имеется 100 наборов данных, то в 5 из них такое расхождение не противоречит гипотезе. Поэтому со статистическим анализом на уровне участков нужно быть осторожным. Выход за 95% доверительный интервал – лишь повод присмотреться к ним. Особенно, если речь идет о психологически предсказуемых числах «0» и «5».
Есть несколько гипотез относительно манипуляции с цифровыми данными. «Жесткая» группа гипотез считает, что это преднамеренные фальсификации с целью изменения результата выборов. Одна из «мягких» - что это лень членов комиссий, которые стараются поскорее закончить работу, считают приблизительно, вписывая психологически приятные им цифры. В последнем случае, результаты выборов искажаются незначительно. Тем не менее, и в том и в другом случае мы будем считать, что имеем дело с искажением волеизъявления избирателя, и наша задача его найти или убедиться в его отсутствии.
Подробнее методах у Bernd Beber and Alexandra Scacco (см. «What the Numbers Say: A Digit-Based Test for Election Fraud», http://pan.oxfordjournals.org/content/20/2/211.full) и у Уолтера Мебейна, Кирилла Калинина «Электоральные фальсификации в России: комплексная диагностика выборов 2003–2004, 2007–2008 гг.» www-personal.umich.edu/~wmebane/falsificacii_reo.pdf).
Метод Бенфорда
Метод Бенфорда, или метод первой цифры, основывается на одноименном законе, который утверждает, что в достаточно больших массивах цифровых данных частота появления первой цифры подчиняется распределению:
P(d) = logb (d + 1) – logb(d) = logb(1 + 1/d)
Сразу нужно сказать, что для электоральных данных закон Бенфорда не работает и не применяется, так как разброс данных недостаточно велик.
Действительно, предположим, у нас есть мощная партия (например, GD в Грузии). Она набирает на участках от 0 до 500 голосов. Но это – не случайные распределения: основная масса результатов лежит в диапазоне 200-300 голосов. Поэтому частота первой цифры - «1» - будет меньше ожидаемых, а выше «5» первых цифр почти не будет. То есть, первые цифры будут концентрироваться на «2» и «3».
Для очень малых партий результат тоже будет отклоняться от распределения Бэнфорда. Предположим, партия набирает голоса в диапазоне 4-5 голосов на участок. Тогда у неё будет нехватка первых цифр в диапазоне от «6» до «9».
Объединение массива данных по всем партиям тоже не даст надежного результата. Объединив мощную GD и малую партию, мы будем иметь дефицит первых цифр в том же районе ( от «6» до «9»). Действительно, для GD – 600 – это уже слишком много. Для малой – 6 голосов, не говоря уже о 60-ти – тоже недостижимая величина.
Реальные цифры выборов 2016 в Грузии подтверждают эти закономерности.
Распределение первых значащих цифр в числе голосов за партии в данных УИКов:
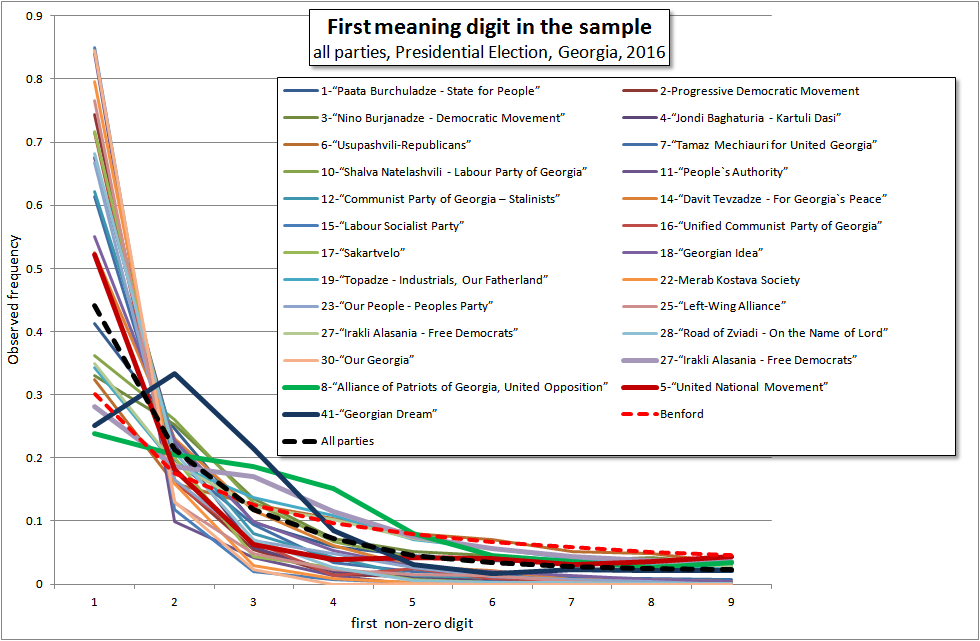
Мы видим ожидаемое отклонение у GD в районе «2»-«3», дефицит у большинства малых партий в больших значениях, отклонения у партий на пороге прохождения в районе «3»-«4» (так как они имеют много УИК 30-40 голосов) и так далее.
Мы приводим этот график лишь для того, чтобы показать, что никаких глобальных аномалий не наблюдается. Распределение числовых величин стремиться к распределению Бэнфорда, но не достигает его из-за описанных ограничений, характерных для избирательных систем.
Метод последней цифры
Метод последней цифры – ещё один признанный способ выявлять фальсификации в больших массивах чисел. Он также применяется в аудите, криминалистике и многих других сферах. Этот список включает и контроль выборов. Я уже упоминал работы Bernd Beber and Alexandra Scacco и Уолтера Мебейна, Кирилла Калинина в качестве примера.
Гипотеза заключается в том, что в больших наборах чисел, где числа достаточно велики (длинны) вероятности появления последней цифры одинаковы. « Достаточны» - т.е. их разброс должен достигать нескольких десятков, чтобы последние цифры стали случайными.
Сразу оговоримся, что в условиях Грузии, где мы имеем множество малых партий и пару «тяжеловесов», метод имеет ограниченное применение. Так как большинство партий не набирает и десяти голосов, то у них первая цифра равна последней и должна стремиться к распределению Бенфорда, а не к равномерному распределению. Действительно, данные выборов 2016 года выглядят так:

Так как мы рассматриваем только значащие цифры, то мы удалили из выборки данные с нулями голосов на участке. В результате у большинства партий «0» и вовсе не наблюдается, так как они не набирают и 10 голосов на участке. В целом, как и предсказывалось, малые партии стремятся к распределению Бенфорда и в последних цифрах за важным исключением. Партии, набирающие несколько десятков голосов, уже соответствуют необходимому критерию.
Действительно, математически, критерий согласия для голосов за UNM, GD и абсолютной явки не противоречит гипотезе равномерного распределения.
χ 2 (UNM) = 8.30 (в теории, такое можно наблюдать каждые вторые выборы)
χ 2 (GD) = 8.08 (также каждые вторые выборы)
χ 2 (turnout) = 11.35 (такие отклонения от ожидаемых величин могут быть каждые четвертые выборы)
Расчёты χ 2 производились по методу, описанному в https://en.wikipedia.org/wiki/Pearson%27s_chi-squared_test#Fairness_of_dice, аналогично это делали Уолтер Мебейн, Кирилл Калинин в www-personal.umich.edu/~wmebane/falsificacii_reo.pdf.
Графически это выглядит так:

Чисто математически, данные не вызывают вопросов. Однако, учитывая человеческую психологию, можно отметить выделяющуюся «5» в голосах UNM, и небольшой, но одновременный избыток нулей сразу по всем трем величинам. Вероятность избытка у трех независимых величин – 12%.
В 2013 году тоже были заметны нули и пятерки:

χ 2 (GD) = 17.03, слегка за гранью доверительного интервала в 95%
В таких случаях принято говорить, что с надежностью в 95% гипотеза о случайном независимом характере величин должна быть отвергнута в пользу альтернативной. Альтернативной гипотезой является предположение, что в данных содержатся следы манипуляций.
Трудно определить характер этих манипуляций. В 2016 году, последняя цифра «5» в результатах UNM находится на грани доверительного интервала. Однако никакой корреляции с результатами это не имеет. То же можно сказать про цифру «0» превышающую среднее одновременно в данных UNM, GD и явке:

Корреляция в пользу UNM пренебрежимо мала. Наиболее вероятное предположение заключается в том, что отклонения по «0» и «5» действительно носят некриминальный характер, например, стремления комиссий к округлению. Berber и Scacco называют эту версию гипотезой «доброкачественной лени» («benign laziness»).
Даже это незначительное отклонение в 2016 году стало менее заметным, по сравнению с 2013.
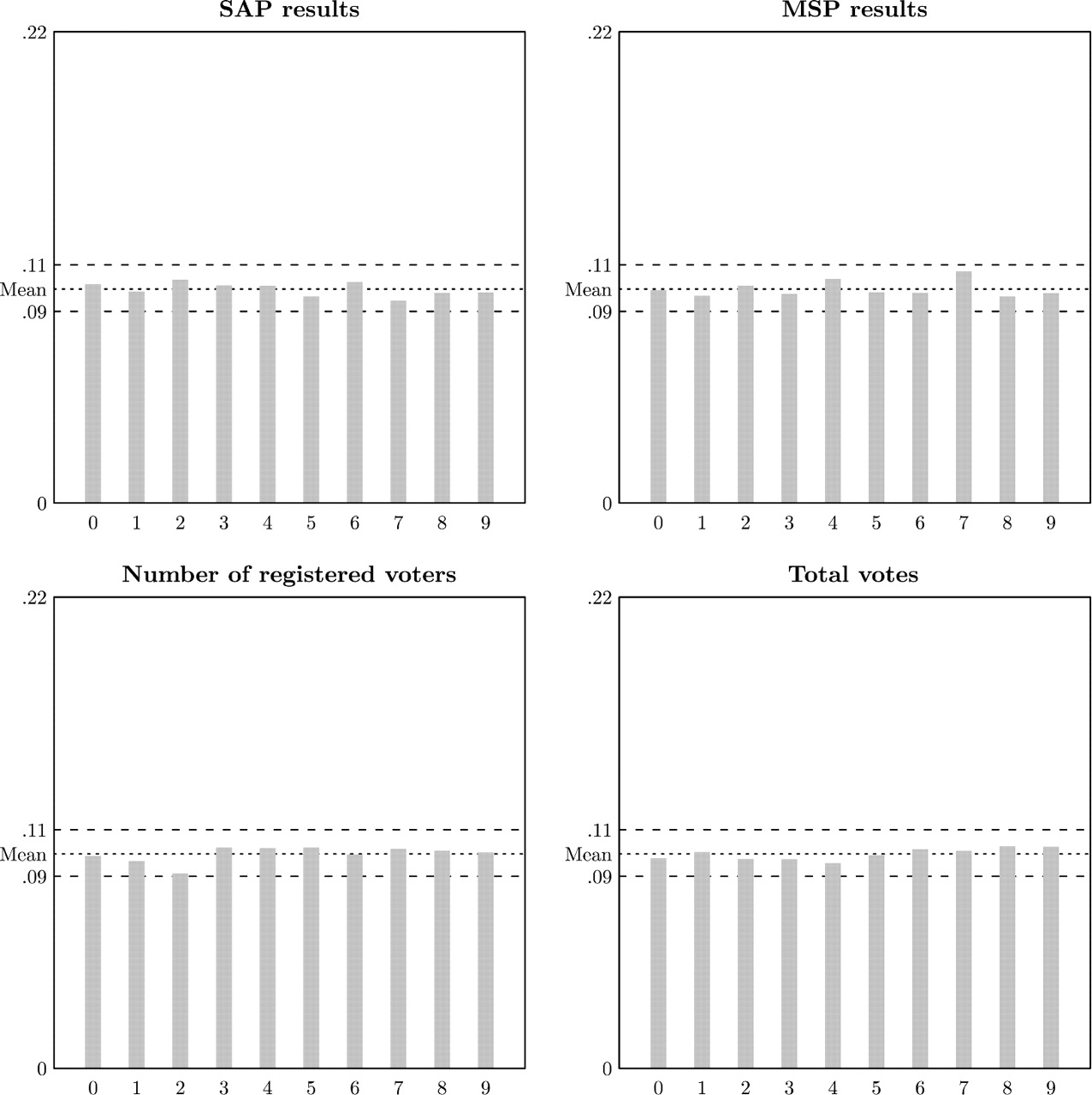
Для сравнения приведу графики выборов в Швеции в 2002 году (5976 участка), считающиеся чистыми.
И африканских выборов, фальсификации на которых подтверждаются фактами.
Нигерия в 2003, штат Plateu (2652 участка):
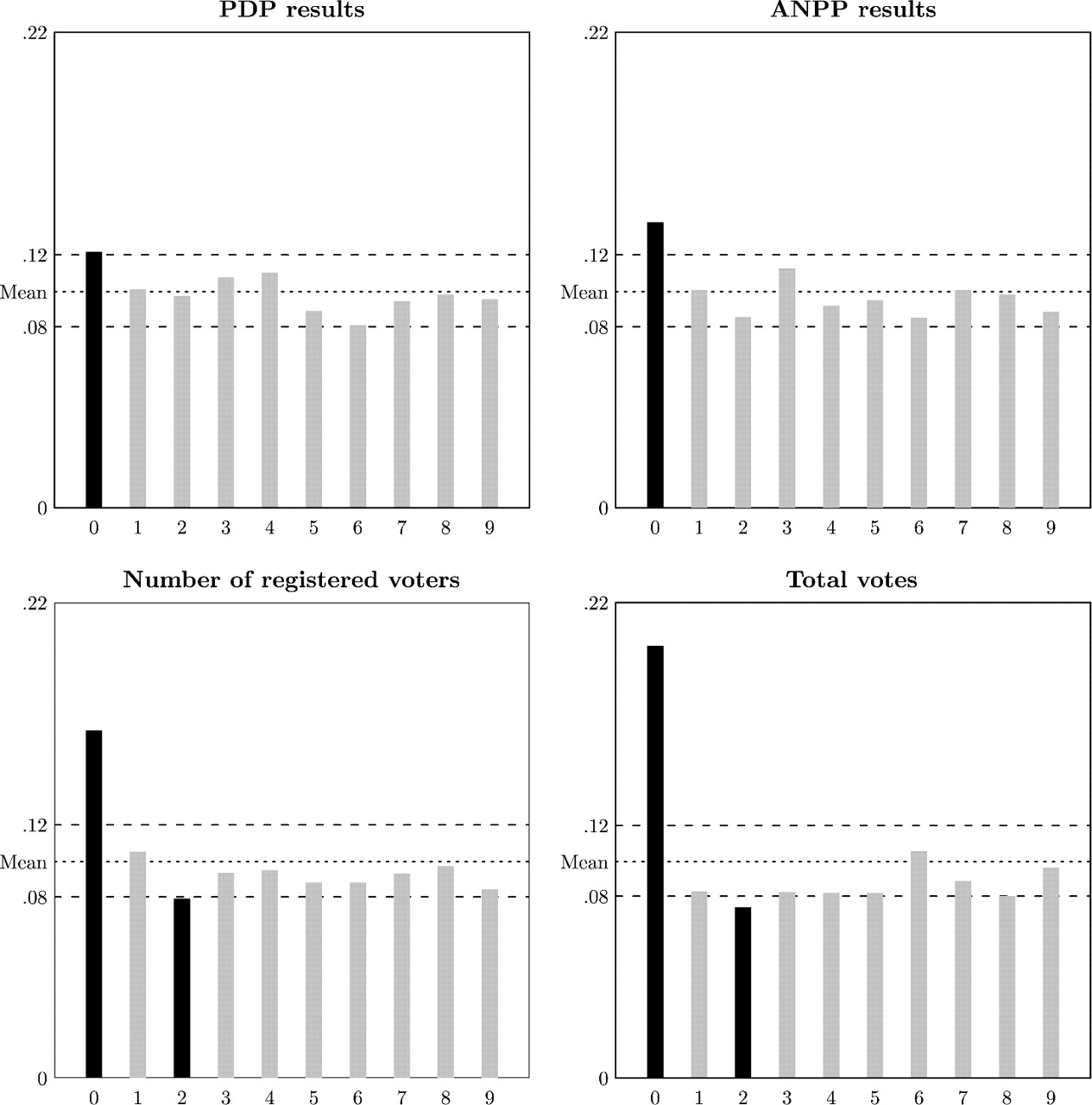
Сенегал в 2007:

(данные по [http://pan.oxfordjournals.org/content/20/2/211.full])
Хотя по всей стране данные не вызывают замечаний, при более детальном анализе можно заметить ряд закономерностей.
Так в 2013 году, в зоне лучшей для GD трети округов, результаты выглядят по-сенегальски:

Выше я уже разделял все участки на три группы - по уровню поддержки GD (худшие, средние и лучшие результаты GD по округам).
Данные за 2016 год по этим группам:



Видно, что в группах уровень отклонений различается. Наибольшие отклонения в той трети округов, где результаты GD были наилучшими.
Если сконцентрироваться на аномальном «хвосте» GD, то там как в 2013 так и в 2016 году наблюдались отклонения.
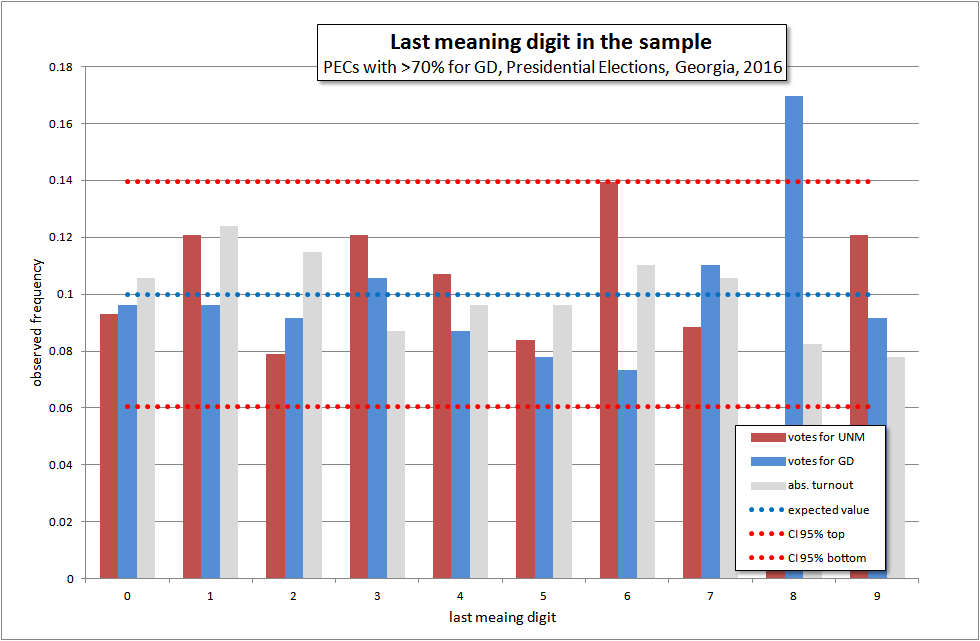
Этот регион, который давно привлекает наше внимание, содержит в 2016 году сразу два отклонения:
χ 2 (GD) = 14.20183 и χ 2 (UNM) = 14.34884
Тот же «хвост лучших» в 2013 году тоже содержал небольшие аномалии:

Рассматривая аномальный «хвост» GD, нужно сказать, что число рассматриваемых участков падает. Хотя при этом доверительный интервал 95% расширяется, но данные все равно выходят за его пределы. Тем не менее, нужно учитывать, что результаты даются целью привлечение внимания к этой группе участков, а не для окончательных утверждений о наличии манипуляций. Вопрос должно решить непосредственное наблюдение и сбор сообщений об обнаруженных нарушениях.
С той же целью - исключительно для иллюстрации и привлечения внимания - я привожу данные более мелких наборов данных.
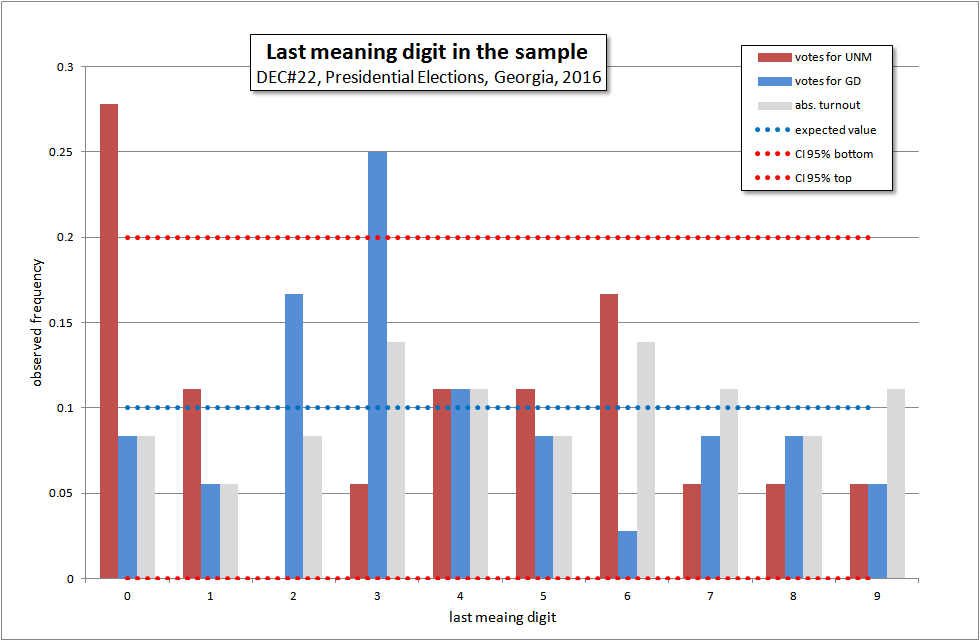
Зона аномально высоких результатов GD в основном состоит из округа №53 в 2016 году. В последних цифрах там тоже прослеживаются аномалии, выходящие за 95% доверительный интервал:

За доверительный интервал выходят округа:
По голосам за GD #4, #5, #21, #26, #31, #37, #52, #57
По голосам за UNM #2, #22, #33, #35, #41, #66, #69
Выглядит это так:


Характерный избыток «0» тоже местами наблюдается:


Я уже упоминал выше ошибки первого рода, или «ложные срабатывания» при статистической проверке гипотез. Например, если наблюдаемые величины вышли за доверительный интервал в 95% принято отвергать гипотезу. Однако если у нас имеется 100 наборов данных, то в 5 из них такое расхождение гипотезой предусмотрено. Это и есть «ложное срабатывание». В нашем случае, при 74 округах, ожидаемое число «ошибок первого рода» - 3 -4 по каждой цифре. Поэтому со статистическим анализом на уровне участков нужно быть осторожным. Выход за 95% доверительный интервал – лишь повод присмотреться к ним. Особенно, если речь идет об участках, выделяющихся по другим параметрам, как это происходит с «хвостом лучших» GD.
Тем не менее, данные по всем участкам страны или по их большим группам (трети), дают возможность утверждать, что в них содержатся следы каких-то манипуляций.
Если использовать термин «статистический шум», то шум по всем цифрам повышен в наиболее благосклонной к GD трети округов. В аномальном «хвосте» GD – он ещё более заметен.
Как в случае и с графическими методами, отклонения небольшие. На уровне страны они существуют, но влияние их на результат не обнаружено. На уровне групп округов они указывают на повышенные манипуляции в областях с лучшими для GD результатами, что может вызывать определенное недоверие к этим результатам. На уровне индивидуальных округов, эти отклонения могут лишь требовать повышенного внимания к соответствующей группе участков.

